Data Exfiltration with Github.com as a vector
This article outlines a method for data exfiltration via GitHub’s file uploader. The process involves creating a GitHub repository, uploading files, and committing them. Threat actors may initially upload a few files, wait, then upload more, while staying within GitHub’s 100-file limit. To erase evidence, they may use a remote server to pull commits and delete the repository or commits. The article highlights the need to check commit history for deleted files and mentions that no known prevention methods exist. The author suggests that GitHub could develop new rules or heuristics, possibly using deep learning, to address the issue.
Getting Started
-
Create a new repository on github.com
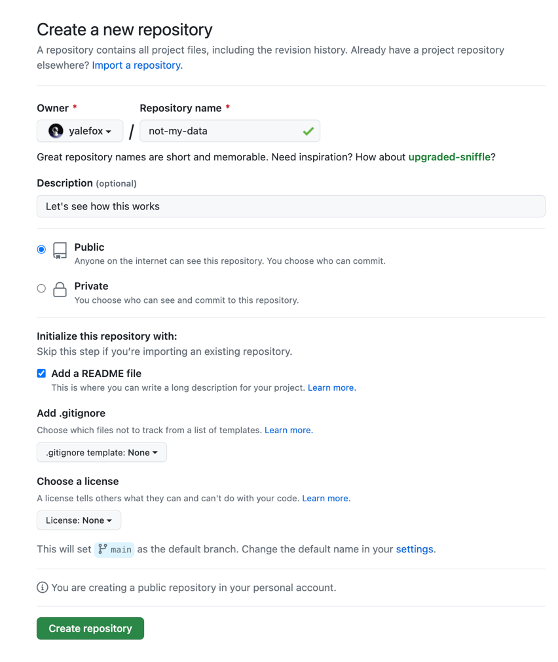
-
Upload a few files using the web portal.
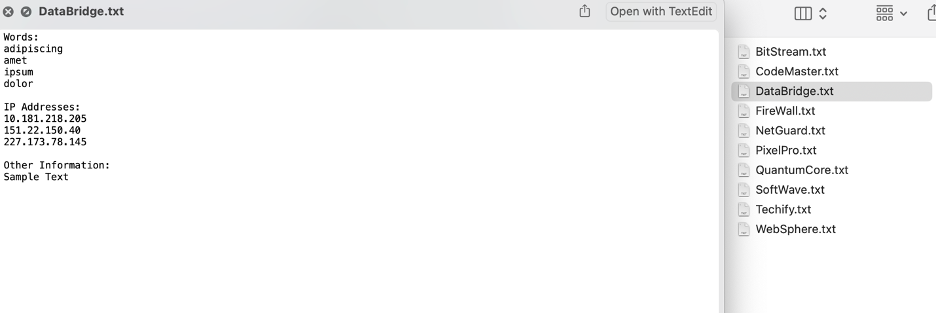
Typically, threat actors use this to test the waters on what kind of data they can get out. I used a python script to generate a series of fake textfiles stuffed with all sorts of keywords that should set off heuristics somewhere. -
Go to the GitHub page of the newly created repository: https://github.com/yalefox/not-my-data
-
Click on the Upload Files button to upload them into Github
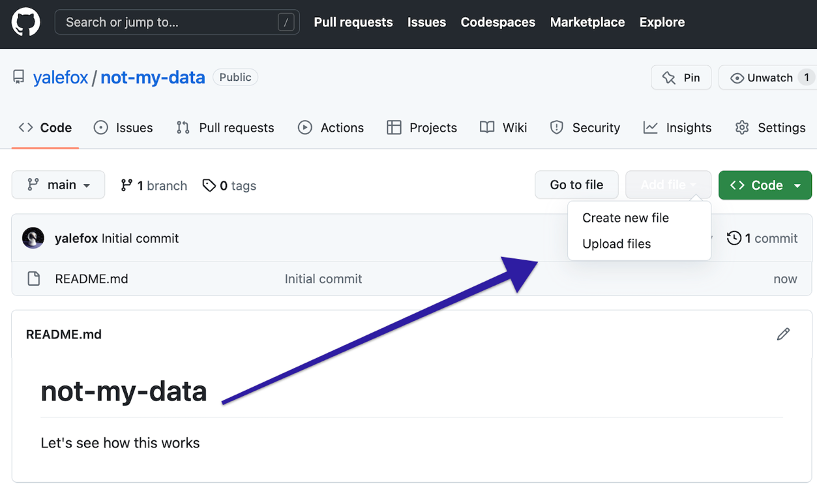
-
And then commit the files
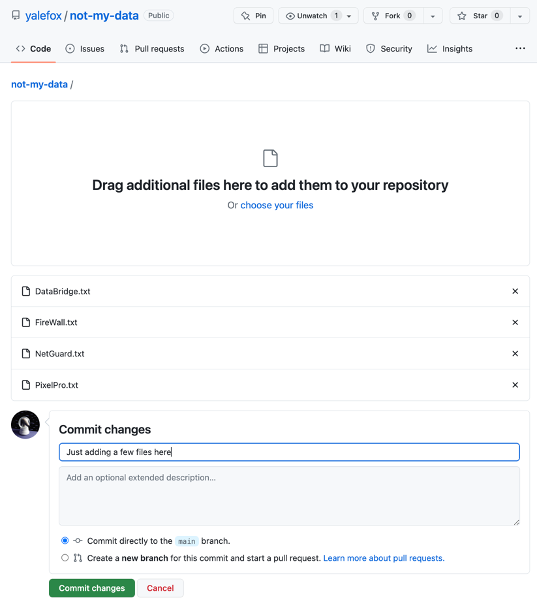
⚠️ Note: This technique often involves uploading a few files initially, waiting a few weeks, and then uploading more.
Keep in mind that GitHub has a 100 file max.
- Clean up your tracks (optional)
Set up a remote server that automatically pulls commits every 5 minutes, then wait 5 minutes and either delete the repository entirely, or delete the commits by using drop, squash or rebase.

After deleting the files from git, you’ll notice that it still says there are 14 commits but looks as if there are only two files in there:
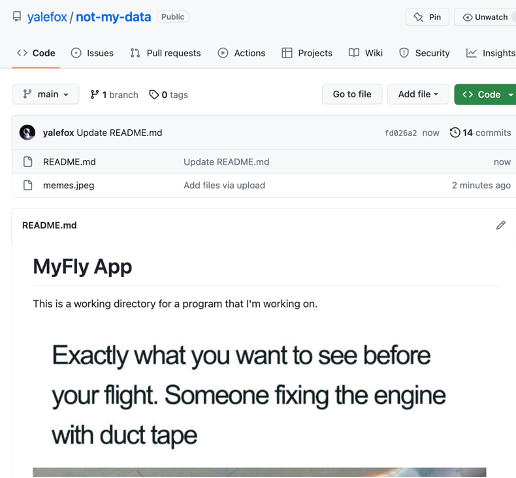
This is why cybersecurity analysts and threat hunters who are falling victim to these type of data exfiltration techniques should always look inside the commit history:

Read more relevant content

Decorrelation stretching enhances color differences in images, making it easier to distinguish between different features. It has been used to find cave art, identify minerals and ore deposits, and map land cover types.

Home Assistant is a versatile open-source platform that empowers users to automate almost any aspect of their daily routines, not only for activities inside their home such as lighting and heating but also extends to processes beyond the walls of their home.

Web servers are a critical component of web applications, and the choice of a web server depends on various factors like traffic volume, resource requirements, server features, and complexity. Some real-world situations where the popular web servers like NGINX, Apache HTTP Server, LightHTTPd, and OpenLiteSpeed are suitable for use are discussed.